Bayesian Inference with MCMC
MCMC 기억 되살리기
For what
- 베이지언 추론에 관해서 수박 겉핥기로 살펴본다.
- MCMC의 기본 논리를 정리한다.
Bayes’ theorem
$P(A)$는 prior, 즉 사전 확률이다. 즉, $A$의 발생 확률에 관한 사전적인 기대 혹은 지식이다. 때로는 기저 확률이라고도 부른다. 이 지식을 $B$라는 증거(evidence)를 통해서 업데이트하는 것이 베이즈 정리다. 이때 업데이트하는 $( )$ 부분이다.
베이즈 정리의 흔한 하지만 언제나 재미있는 사례를 위 식을 통해 다시 들여다보자. 어떤 질병의 정탐(true positive) 확률, 즉 검사의 양성 판정이 곧 발병을 의미할 확률이 매우 높다고 하자. 이때 어떤 사람이 양성 판정을 받았다면, 이 사람은 매우 높은 확률로 해당 질병에 감염된 것일까? 말장난 이것 같지만, 직관적으로는 그럴 것 같다.
해당 질병에 걸릴 확률 자체가 낮다면, 즉 기저 확률이 낮다면, 질병에서 양성 반응이 나왔다는 사실만으로는 해당 질병에 정탐 확률 만큼 높게 감염되었다고 보기 어렵다. 정탐 확률은 베이즈 정리에서 업데이팅 파트를 의미하고, 해당 질병에 걸릴 확률은 기저 확률에 해당한다. 기저가 매우 낮다면, updating 부분이 높아도 사후 확률은 그렇게까지 높지 않을 수 있다.
베이즈 “착각”은 흔하게 발생한다. 우리가 흔히 접하는 확률은 정탐 확률이다. 즉 99% 정확도라고 하면 질병이 있을 때 이를 탐지할 확률 ($P(B \lvert A)$)이다. 위에서 듯이, 이는 양성 결과를 받을 때 병에 걸렸을 확률과는 다르다.
Bayesian inference
- 추정이란 모집단에서 얻은 샘플을 통해서 모집단 분포의 특성(파라미터)를 추측하는 과정이다. 추정을 위해서 필요한 것은 ‘분포’다. 베이즈 정리에 기반해 사후 분포를 구하는 방법은 아래와 같다.
각각 나누어 살펴보자.
- $P(data)$: evidence, 데이터를 관찰할 확률을 뜻한다.
- $p(data\lvert \theta) = {\mathcal L}(\theta\lvert data)$: Likelihood, 관찰된 데이터의 ‘우도’ 혹은 가능도를 나타낸다.
- $p(\theta)$: prior, 데이터를 포함하지 않은 파라미터의 사전 분포를 뜻한다.
- 파라미터 공간은 n 차원 벡터다. $\theta \in \mathbb R^n$, $\theta = (\theta_1, \theta_2, \dotsc, \theta_n)$.
식의 분자는 모두 파리미터 $\theta$의 함수다. 분모는 상수다. 뒤에 다시 설명하겠지만, $p(\theta \lvert data)$를 $\theta$에 대해서 최적화한다면, 분자만 고려하면 된다.
대소문자를 구별해서 쓴 것에 유의하자. 소문자 $p$는 확률 분포, 즉 확률 밀도 함수(pmf) 혹은 확률 질량 함수(pdf)를 뜻한다. 대문자 $P$는 확률이다.
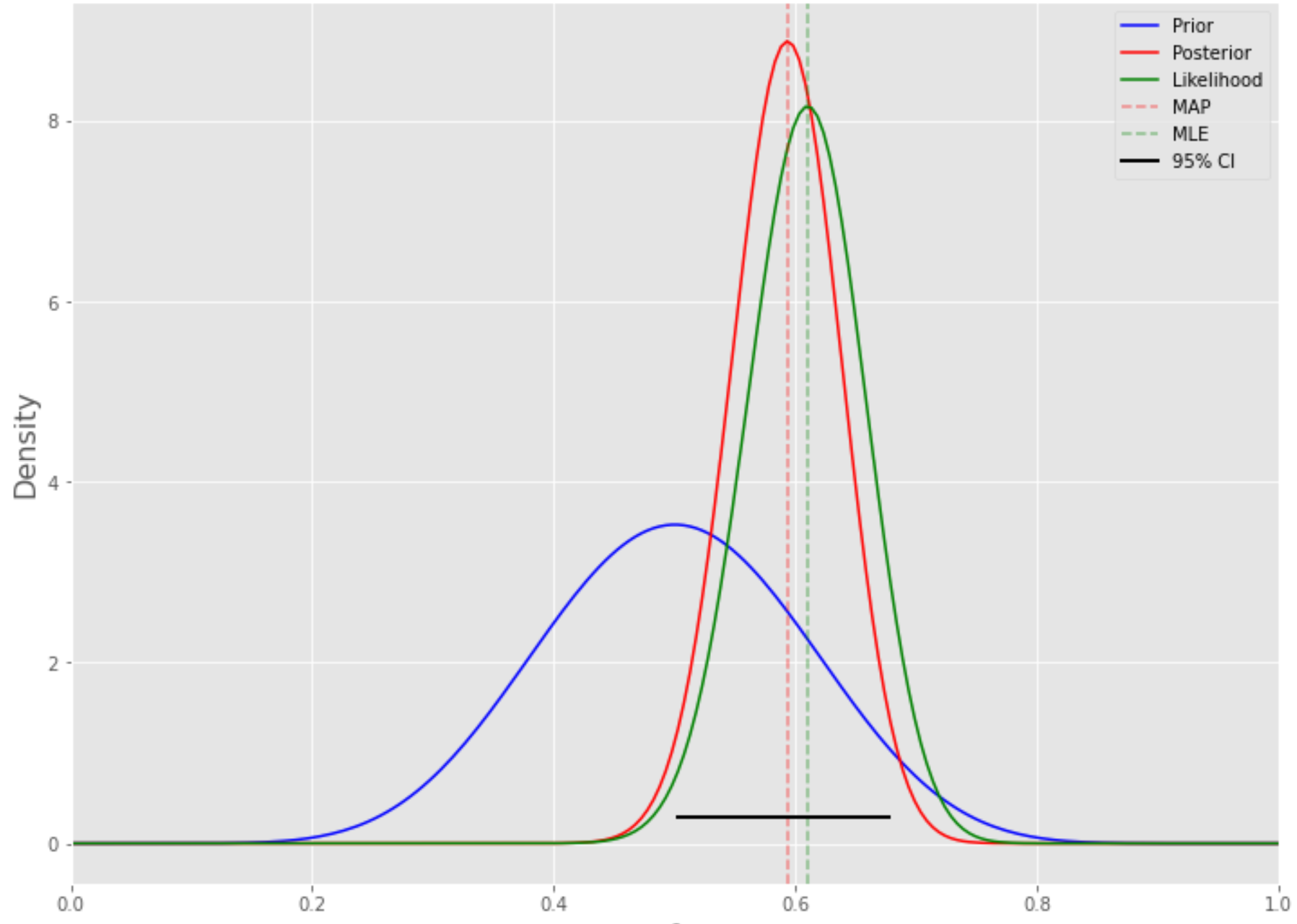
위 그림을 보자. 사전 분포는 우도에 따라서 재평가 되면서 사후 분포를 만들어 낸다. 우도(때로는 가능도라고 표현하기도 한다)에 관해서 조금 더 살펴보자.
Something about likelihood
관찰된 $data$ 아래에서 이 결과가 가능한 ‘정도’를 파리미터의 함수로 나타낸 것, 정도로 이해하면 좋다. 우도를 의미할 때 ‘확률’이라는 표현을 쓰지 않은 것이 좋다. 왜 그럴까?
Probability vs Likelihood
이산 분포에서 확률 = 우도?
이산 분포에서는 특정한 파라미터에서 1개의 데이터를 관찰할 때 확률과 우도가 같다. 이는 probability mass function(pmf)이 그 값을 관찰할 확률과 같기 때문이다. 하지만 우도를 구할 때 $data$가 꼭 하나 여야 할까? 이는 어떤 데이터를 보고 업데이트하는지에 달려 있다.
예를 들어보자. 동전을 던져서 HH를 관찰했다고 하자. 동전의 앞면이 나올 확률이 $p$라고 하고 독립 시행이라면, 이는 $p^2$가 이 관찰 결과의 ‘우도’이다. 물론 이는 HH라는 결과를 얻을 확률이기도 하다.
이렇게 표현해보자. 이는 HH가 관찰되었을 때 $p=0.5$라는 파라미터의 가능도가 $0.5^2$라는 뜻이다. 즉,
사족이지만, HH가 관찰되었을 때 $p=0.5$일 확률이 $0.25$이라는 말은 아니다. 즉,
연속 분포에서 확률 $\neq$ 우도?
연속 분포에서 우도는 probability density function(pdf)과 같다고 설명되어 있는 경우가 있다. 이 말은 맞기도 하고 아니기도 하다. $data$의 관찰 수가 1개라면 이 말은 맞다. 하지만, 이산 분포의 경우와 같이 2개 이상일 때는 pdf와 우도가 같다고 말할 수 없다. 최우추정법에서 pmf 혹은 pdf가 곱해진 형태를 떠올리면 이해가 조금 쉬울 수 있겠다.
우도는 pmf 혹은 pdf일까?
관찰이 1개라면 앞서 보았듯이 우도는 pmf 그리고 pdf가 된다. pdf가 된다는 것은 무슨 의미일까? 파라미터 공간 전체에 대해서 합하면 혹은 적분하면 1이 되어야 한다. 그래서 pdf다. 그런데 일반적으로 우도를 적분을 한다고 해서 1이 되지 않는다. 앞서 보았던 예로 가보자.
그렇다면 사후 분포 $P(\theta\lvert data)$는 혹은 pmf인가 pdf인가? 그렇다. $\int_\theta P(\theta\lvert data) d \theta$를 구하면 1이다.
How to infer
- 베이즈 추론에서 아래의 표현을 많이 접하게 된다.
왜 온전한 $p(\theta\lvert data)$를 구하지 않고 분모를 제외하려고 할까?
이유는 두 가지다. 첫째, 베이즈 추론에서 우리의 목적함수는 $p(\theta\lvert data)$다. 즉, 이 값을 극대화해주는 $\theta$를 찾는 것이 목적이다. 이렇게 보면, MLE와 사실상 같은 방법이라고 할 수 있다. 분모의 $P(data)$에는 $\theta$가 없다. 즉, 목적함수를 극대화하는 파리미터를 찾는 데 분모는 영향을 주지 않는다.
둘째 $P(data)$는 계산하기가 만만치 않다. 많은 경우는 아예 불가능하다. 예를 들어 $\theta$가 다차원이라면 적분이 아예 불가능할 수 있다. MCMC에서 이 문제를 다시 볼 것이다.
어쨌든 해당 목적 함수의 최적화를 통해 찾은 파라미터를 MAP(Maximum A Posteriori)라고 부른다. MAP은 posterior의 mode(최빈값)이기도 하다. MAP은 $p(\theta\lvert data)$는 분포에서 가장 높은 봉우리를 지니는 파라미터를 찾는 것인데, 이는 해당 값이 가장 많이 나오는 값이라는 뜻이기도 하다.
MAP vs MLE
만일 prior에 해당하는 모든 파라미터 공간에서 적절한 $k$에 대해서 $p(\theta) = k$로 둔다면, 즉 prior에 관해 특별한 가정을 하지 않는다면, 이는 MLE와 동일한 값이 될 것이다. 모든 파라미터 공간에 대해서 동일한 사전 분포를 부여한 형태가 MLE라고 이해하면 되겠다. MLE $\subset$ MAP
MCMC!
Why?
MCMC는 Markov Chain Monte Carlo Simulation의 약어다. 둘을 각자 하나씩 뜯어보기 전에, 왜 MCMC라는 걸 고민하게 되었을까? 이유는 간단하다. 앞서 베이즈 추론에서 보았지만, $\mathcal L (\theta\lvert data) p(\theta)$는 쉽게 구할 수 있다.
- 사전 분포 $p(\theta)$는 내 마음대로 정하면 되는 것이다.
- 여기에 $data$, 즉 관찰을 부어 넣으면 우도가 된다.
MAP 혹은 MLE 형태의 ‘추정치’만을 얻고 싶었다면 여기서 더 고민할 게 없다. 하지만 추정치를 얻었다면 검정을 해야 한다. 베이즈 추론의 강점은 파라미터를 직접 추정하고 이 추정치가 참일 확률을 직접 계산할 수 있다는 데 있다. 빈도주의 추론처럼 빙빙 돌리지 않는 것이 베이즈 추론의 강점이다. 그런데 이것을 하려면 $\theta$의 분포가 필요하다…
문제는 위 식의 적분, 특히 $p(\theta)$ 분포를 포함한 적분이 쉽지 않다는 데 있다. Prior가 계산 가능한 수준이라고 해도 $\theta$가 $n$ 차원의 벡터일 수 있다. 이를 정확하게 계산해서 해석 해(analytic solutions)를 얻는 것은 대체로 가능하지 않다.
First MC: Monte Carlo
사실 이럴 때 동원할 수 있는 방법이 몬테카를로 시뮬레이션이다. 해석 해를 구할 수 없지만 어떤 파라미터 포인트 $\theta_i$ 를 넣으면 $\mathcal L(\theta_i\lvert data)(=p(data\lvert \theta_i))$는 알 수 있다. $\theta_i \in \theta$를 충분히 많이 뽑아서 평균을 내면 $P(data)$가 되지 않을까?
이해를 돕기 위해서 일변수 함수로 다시 표현해보자. 어떤 함수 $f(x)$를 계산할 수 있고 $p(x)$를 샘플링할 수 있다고 하자. 우리가 구하고 싶은 것은 아래의 적분 값이다.
해석 해가 불가능해도 샘플링이 가능하면 해석 해의 근사치를 얻을 수 있다. 즉, 적당히 많은 수, 즉 $N$ 개의 $X_i$를 샘플링해서 $f(X_i)$를 얻어 평균값을 구하면 된다. 즉,
여기서 잠깐! 식의 오른 쪽에 $p(x)$가 사라졌다는 점을 주목해서 보자. 왜 일까? $X_i$를 샘플링했다는 것, 즉 $p(x)$가 샘플링 가능했다는 것은 왼쪽 적분 식에서 $p(x)$의 분포를 고려해서 $X_i$를 뽑았다는 이야기다. 즉, 분포에 맞게 $X_i$가 뽑혔다는 것은 $X_i$가 많이 분포한 영역에서 많이 뽑히고 적게 분포한 영역에서 적게 뽑힌 것이다. 따라서 $f(X_i)$의 단순 평균으로 적분 값은 근사할 수 있게 된다.
Second MC: Markov Chain
몬테카를로에서 끝났다면 그래도 편했을 것이다. 샘플링을 할 수 있다면, 하자! 샘플링이 ‘충분히’ 쉬울까? 파라미터의 차원이 3개만되도, 샘플링을 위해이 탐사해야 하는 파리미터의 공간이 많이 커진다. 이런 상황에서 샘플링을 하는 것 자체가 어렵게 된다.
샘플링을 잘 하기 위해서는 이를 위한 전략이 필요하다. 관찰이 많이 될 것 같은 파라미터 공간 주변에서는 많이 뽑고, 별로 없을 것 같은 공간 주변에서는 적당히 뽑은 후 빨리 빠져나올 수 있어야 한다. 이런 좋은 샘플링 전략의 그럴듯한 근거를 제시하는 것이 또다른 MC, 마르코프 연쇄이다.
마르코프 연쇄가 왜 이런 전략을 제공할까?
- 마르코프 연쇄는 간단하다. 바로 전기의 상태가 다음 기의 상태를 결정하는 최소 기억의 구조를 지니고 있다. 그래서 전략을 만들기 쉽다.
- 마르코프 연쇄의 가장 좋은 특징: 몇 가지 조건이 충족되면 파라미터 공간 위의 ‘수렴’ 분포가 존재하며 이 분포가 고유(unique)하다. 게다가 이 수렴 분포는 초기 값에도 의존하지 않는다.
- 마르코프 연쇄를 통해 충분히 많은 수의 샘플링을 거치면 그때까지 획득된 결과를 파라미터 공간에 관한 분포의 근사치로 간주할 수 있다.
이렇게 얻은 수렴 분포가 $p(data)$의 분포와 일치하면, 끝이다. 해당 샘플링의 결과가 우리가 알고 싶은 분포의 쓸만한 근사치가 된다.
Magic of MCMC
MCMC에서 몬테카를로 부분은 그리 놀랄 게 없다. 자연스럽다. 깜놀할 부분은 마르코프 연쇄 부분이다. 파라미터의 분포를 수렴 분포로 지니는 이행 확률 혹 마르코프 연쇄의 밀도 함수를 우리는 알지 못한다. 이 상태에서 어떻게 파라미터의 분포의 근사치를 얻을 수 있다는 말인가? MCMC의 핵심은 이 수렴분포로 접근하게 만드는 효과적인 이행확률을 만들어내는 데 있다.
해법은 임의의 적절한 밀도 함수가 파리미터의 분포를 따를 수 있도록 규칙을 부여해주는 것이다. 이 역할을 수행하는 것이 Metropolis 알고리듬, M-H(Metropolis-Hastings) 알고리듬이다. 다행스럽게도 이 규칙들이 복잡하지 않고 간단하다. 이것이 마법이다! 이렇게 임의로 만들어진 밀도 함수가 원하는 파라미터의 분포를 유일한 수렴 분포로 지니기 위해서는 마르코프 연쇄의 어떤 속성들을 지니고 있어야 한다. 이는 이른바 detailed balance 조건을 통해 보장된다. 즉,
이를 앞서 적은 식의 맥락에서 다시 풀어보자.
여기서 $\theta^k$는 마르코프 연쇄 위에서 얻은 $\theta$의 수열을 뜻한다. 정리하면 파라미터의 사후 분포를 수렴 분포로 지니는 마르코프 연쇄의 어떤 밀도 함수(이행 행렬)를 구성하고, 이 밀도 함수가 detailed balance를 만족시키면 되겠다.
Metropolis algorithm
- 이행 행렬로 임의의 밀도 함수 $Q(\theta^i \lvert \theta^{i-1})$를 정하자. 이를 밀도함수로 받아들일지 여부를 아래와 같은 확률로 결정한다. 이를 수용확률이라고 부른다.
- 즉, 이전값($\theta^{i-1}$)보다 새로운 값($\theta^i$)이 더 큰 확률을 주면, 이 밀도함수를 1의 확률로 받아 들인다. 반면 그렇지 않으면 확률의 크기에 따라서 이를 수용한다. 이제 $\theta^{i-1} = \theta^a$에서 $\theta^i = \theta^b$, 즉 $\theta^a \to \theta^b$ 로 이행할 확률을 구해보자. 만일 $\pi(\theta^a\lvert data) \leq \pi(\theta^b\lvert data)$라고 해보자.
- $\pi(\theta^a)$, 즉 $(\ast)$ 그냥 prior를 통해 쉽게 구할 수 있다. $(\ast\ast)$ 역시 어렵지 않게 구할 수 있다.
이번에는 detailed balance를 살펴보기 위해서 반대로 $\theta^b \to \theta^a$를 구해보자.
- 메트로폴리스 알고리듬의 가정 중 하나는 이행 행렬이 대칭이라는 것이다. 즉, $Q(\theta^b\lvert \theta^a) = Q(\theta^a\lvert \theta^b)$. 따라서 detailed balance가 성립한다. $\pi(\theta^a\lvert data) > \pi(\theta^b\lvert data)$인 경우에 대해서도 비슷하게 도출할 수 있다.
Metropolis-Hastings algorithm
- M-H 알고리듬은 임의의 밀도 함수, 즉 $Q(\cdot)$가 대칭이라는 제약도 풀어버린 것이다. 수용 확률 $r$ 이 다음과 같이 정의된다.
- Metropolis 알고리듬의 사례에 제시된 바를 따라가보면 대칭이라는 조건 없이 detailed balance를 만족한다는 사실을 쉽게 계산해볼 수 있다.
Toy code
# Computation
import scipy as sp
import scipy.stats as st
import numpy as np
# Vis
import matplotlib.pyplot as plt
import seaborn as sns
# Definition
thetas = np.linspace(0, 1, 200)
prior = st.beta(a, b)
post = prior.pdf(thetas) * st.binom(n, thetas).pmf(h)
post /= (post.sum() / len(thetas))
# Func for metropolis algorithm
def target(lik, prior, n, h, theta):
if theta < 0 or theta > 1:
return 0
else:
return lik(n, theta).pmf(h)*prior.pdf(theta)
# Parameters
n = 100
h = 61
a = 10
b = 10
lik = st.binom
prior = st.beta(a, b)
sigma = 0.3
naccept = 0
theta = 0.1
niters = 10000
samples = np.zeros(niters+1)
samples[0] = theta
# Iteraton
for i in range(niters):
theta_p = theta + st.norm(0, sigma).rvs()
rho = min(1, target(lik, prior, n, h, theta_p)/target(lik, prior, n, h, theta ))
u = np.random.uniform()
if u < rho:
naccept += 1
theta = theta_p
samples[i+1] = theta
nmcmc = len(samples)//2
print (f"Efficiency = {naccept/niters}")
코드에 관한 설명은 간략하게 하겠다. 코드의 출처는 여기를 참고하라. 진행은 다음과 같다. 이 코드는 다음과 같은 베타 분포, $\beta(a, b)$를 사전 확률로 지닌다. 사후 확률은 사전 확률의 pdf와 이항 분포 $B(n, p)$의 pmf를 곱이 사후 확률의 분자가 된다. 식에서 $p = h / n$으로 두면 된다. 이때 사후 분포의 근사치를 어떻게 만들어낼 것인가?
- 사전 분포 $\beta(a, b)$를 잡는다.
- 우도는 이항분포의 pmf를 활용한다. 이때 $n$, $h$의 값이 필요하다.
- 아래와 같은 실행을 10,000 번의 실행을 반복한다.
- 최초의 theta는 0.1로 둔다.
- 임의의 theta 값을 정규 분포값에서 생성해낸다.
- metropolis 알고리듬에 따라서 이 값과 최초의 theta 혹은 바로 전에 생성된 theta, 두 값을 평가한다. 평가는 극도로 단순한 방식으로 진행된다. 각기 다음 상태로 넘어갈 확률은 전기의 파라미터에만 의존한다.
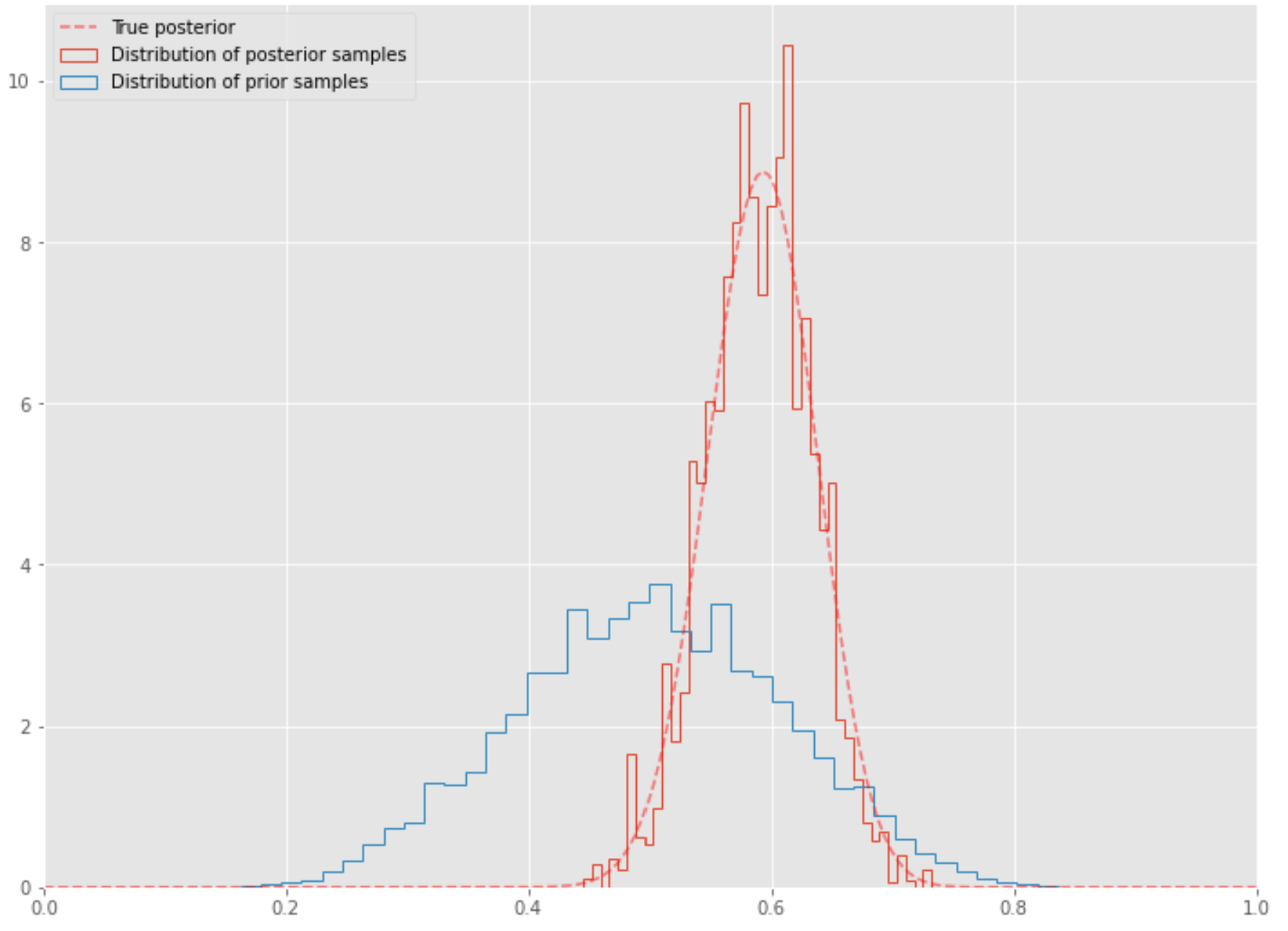
위 시각화의 코드는 다음과 같다.
post = st.beta(h+a, n-h+b)
plt.figure(figsize=(12, 9))
plt.hist(samples[nmcmc:], 40, histtype='step', density=True, linewidth=1, label='Distribution of posterior samples');
plt.hist(prior.rvs(nmcmc), 40, histtype='step', density=True, linewidth=1, label='Distribution of prior samples');
plt.plot(thetas, post.pdf(thetas), c='red', linestyle='--', alpha=0.5, label='True posterior')
plt.xlim([0,1]);
plt.legend(loc='best');
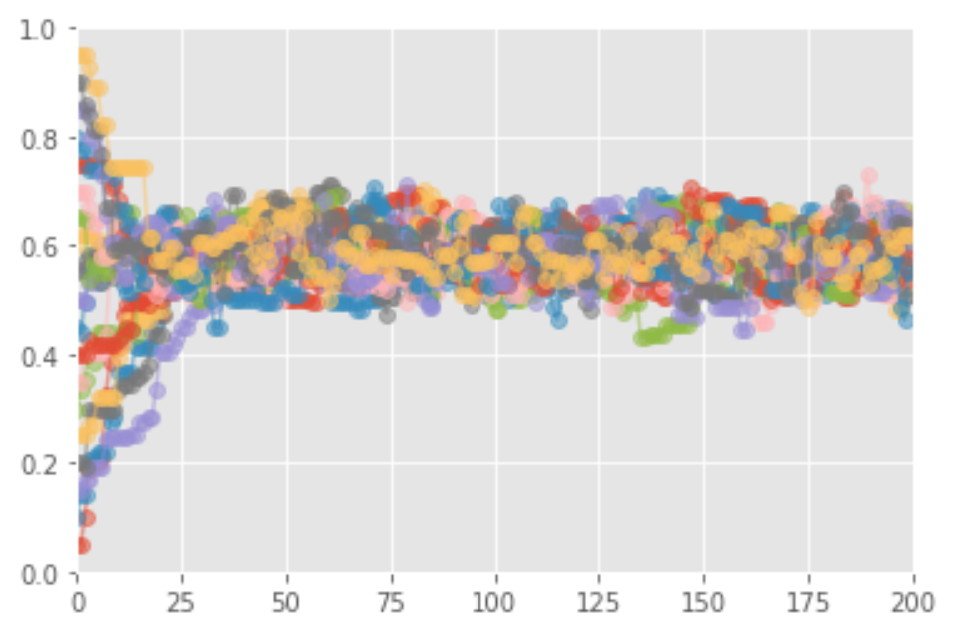
그림에서 보듯이 MCMC가 사후 확률을 잘 따라가고 있다. MCMC는 정말로 잘 수렴할까? 즉, 이론대로 어떤 파라미터에서 출발하더라도 비슷한 분포로 수렴할까? 분포의 수렴은 수치적으로는 따지기 쉽지 않은 개념이다. 느낌만 보도록 하자. 아래에서 보면, 초기값이 관계 없이 모든 값에서 사후 분포에 수렴하는 것을 확인할 수 있다. 즉, $x$ 축에 표시된 반복 횟수가 일정 수준을 넘어서면 모든 마르코프 연쇄가 사후 분포 범위 안에서 움직이고 있다.