Metrics for Binary Classification
이항 분류 지표 정리
Mission
- 자꾸 까먹어서 기회가 될 때 한번 정리해두고자 한다.
- 전공이 아니어서 그런가, 자꾸 까먹는다.
Basic to Remember
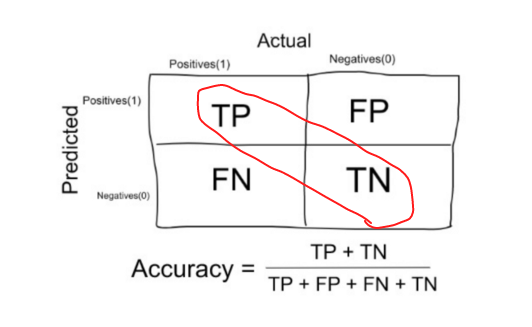
- 로(행)는 예측치를 컬럼(열)은 실제 속성을 나타낸다.
- 이에 따라서 4개의 컨퓨전 매트릭스 행렬이 생긴다.
- 한가지 외우는 팁을 알아보자. 앞에 붙은 True/False의 형용사는 실제 속성(컬럼)에 따라서 결정된다. 반면 뒤에 오는 Positive/Negative는 예측 모델의 예측(로)을 따른다. 즉,
- True Positive: Positive라는 예측이 맞는 경우다. 즉, 컨퓨전 매트릭스에서 2사분면을 나타낸다.
- True Negative: Negative라는 예측이 맞는 경우다. 즉 4사분면을 나타난다.
- False Positive: Positive라는 예측이 틀리는 경우다. 즉 1사분면을 나타낸다. 오탐이라고도 쓴다.
- False Negative: Negative라는 예측이 틀리는 경우다. 즉 3사분면을 나타낸다. 미탐이라도고 쓴다.
Basic Three
Term
- 용어, 정리하고 가보자.
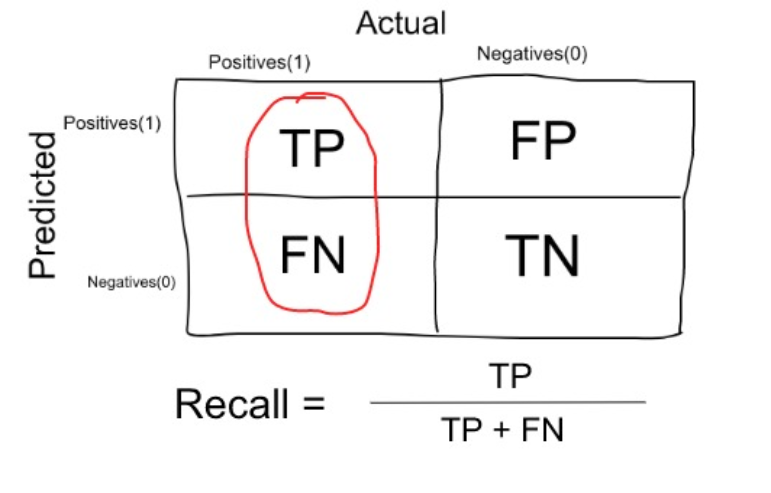
| True Positive Rate (TPR) | False Positive Rate (FPR) | True Negative Rate (TNR) | False Negative Rate(FNR) |
|---|---|---|---|
| Recall | |||
| Sensitivity | 1 - Specificity | Specificity | 1-Sensitivity |
| $\frac{\rm\bold{TP}}{\rm\bold{TP + FN}}$ | $\frac{\rm\bold{FP}}{\rm\bold{FP + TN}}$ | $\frac{\rm\bold{TN}}{\rm\bold{FP + TN}}$ | $\frac{\rm\bold{FN}}{\rm\bold{TP + FN}}$ |
| $1-\beta$ | $\alpha$ | $1-\alpha$ | $\beta$ |
| (1 - type II error) | type I error | (1 - type I error) | type II error |
- 상세한 지표 지도는 여기를 참고하라.
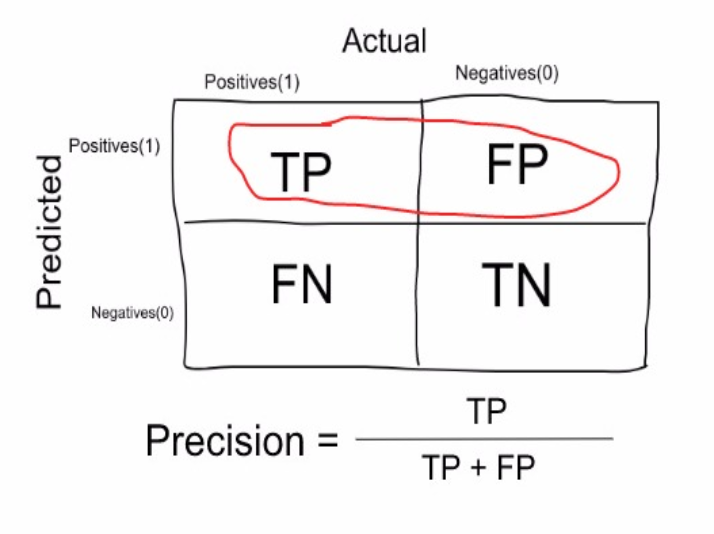
- 따져볼 대목. 위 네 용어는 실제 속성(ground truth)에 기반한 것이다. 즉, 분모에 실제 속성이 깔린다. 반면, 정밀도(precision)와 같은 지표는 예측 값에 기반을 둔다.
ROC curve
- ROC 커브에 이름에 신경쓰지 말자. 어차피 이상한 이름이니까.
- ROC 커브는 무엇에 쓰는 것일까? binary classification에서는 추정된 확률에 대해서 임계 수준을 어디에 둘지에 따라서 해당 결과에 관한 판정을 다르게 내릴 수 있다. 이렇게 다른 임계치를 설정하면서 TPR와 FPR가 변하게 된다. 이 결과를 $x-y$ 평면 위에서 표시한 것이 ROC 곡선이다.
- 컨퓨전 매트릭스에서 컬럼으로 오른쪽의 비율이 TPR, 왼쪽 컬럼의 비율이 FPR을 나타내는 셈이다. 이렇게 보면, ROC 곡선이란 컬럼을 각각 $x-y$ 축으로 쪼개는 개념이다. 컨퓨전 매트릭스에서 컬럼이란 결국 해당 샘플의 실제 속성에 따른 구분이다. 이 점을 잘 기억해두자.
- 이때 TPR는 1이 가장 좋고 여기 가까울수록 좋다. 반대로 FPR는 0에 가까울수록 좋다. 따라서, $x$ 축에 FPR를, $y$ 축에 TPR를 둔다면, $(0,1)$로 갈수록 좋고, $(1,0)$으로 갈수록 나쁜 점이 된다.
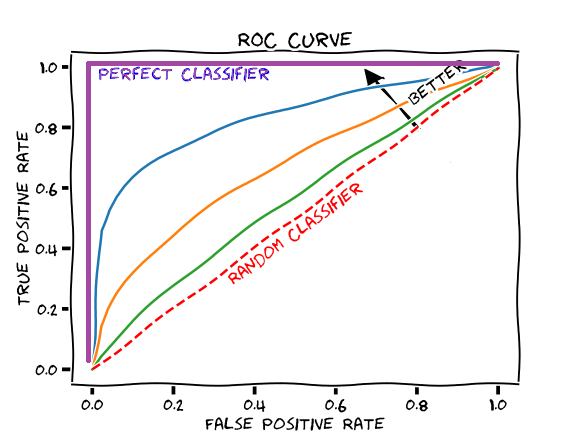
- 경제학에서 쓰는 dominance 개념과 비슷하다. 만일 모든 TPR-FPR 조합에서 어떰 모델의 커브가 다른 모델의 커브보다 $(0,1)$에 근접해 있다면 해당 모델이 우월하다. 만일 둘이 겹치는 영역이 있다면 어떨까?
- 이때 비교를 위해 개발된 지표가 AUC(Area Under Curve)이다. 즉, ROC의 아래 면적의 크기를 구하는 것이다. 설명력이 없는 경우 즉, $(0,0)-(1,1)$ 선의 경우 AUC는 1/2이다. 설명력이 높을수록 1에 가까운 값을 갖게 된다.
F1 Score
- F1 스코어는 별게 아니다. F1 스코어는 accuracy를 보완하는 개념이라고 보면 쉬울 듯 싶다. 분류에서 우리가 타겟으로 삼는 속성이 비교적 고르게 분포한다면(balanced data) accuracy만 보면 된다. accuracy란 전체 샘플에서 예측 모형이 제대로 맞춘 비율을 나타내므로 직관적으로도 분명한 지표다.1
- 그런데, 타겟이 어느 하나로 치우쳐 있다면(imbalanced data) accuracy는 지표로서 힘을 잃는다. 예를 들어 신용우량으로 남는 비율이 전체 샘플의 97%라고 하자. 만일 모든 샘플에 대해서 게으르게 “신용우량”을 판정하더라도 애큐러시는 97%가 된다. 이런 상태에서 애큐러시는 모형을 품질을 나타내는 지표로 기능하기 어렵다. 이런 어려움을 완화하고자 등장한 것이 F1 Score이다.
- F1 Score는 recall와 precision의 조화평균을 나타낸다. 즉.
$$
\dfrac{2}{ \frac{1}{ \text{recall} } + \frac{1}{ \text{precision} } } = 2~ \dfrac{ {\rm recall} \times {\rm precision} }{ {\rm recall} + {\rm precision} }
$$
- 조화 평균이라는 것이 큰 값이 페널티를 주는 방향으로 작용한다. 따라서 F1 Score는 데이터가 치우쳐 있을 경우 사용하는 게 좋다.